Use Cases¶
In this section we show how to both parse and import experiments from various gene expression platforms, technologies and sources (both public databases and local files) using the provided default scripts.
Use Case - Affymetrix from GEO¶
Import Gene Annotations¶
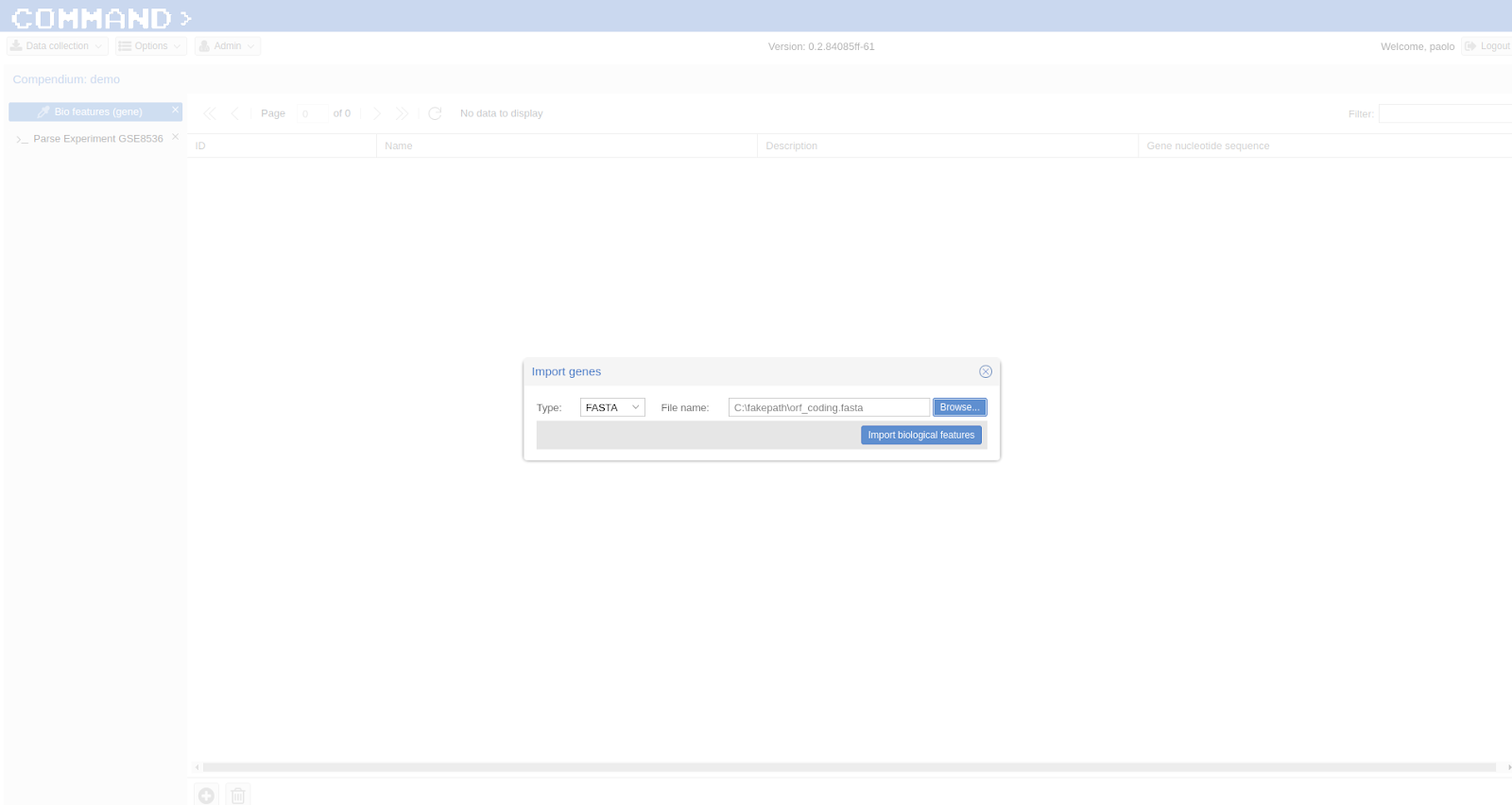
We want to look for experiments related to Yeast: the Saccharomyces Genome Database is the proper choice for retrieving sequences associated to Yeast’s genes (from this link). Go to > Data collection (on the top left corner) then > Biological features > Import biological feature (+ symbol on the bottom left) > Type: FASTA , File name: select the annotation file you downloaded before > Import Biological features. Wait.
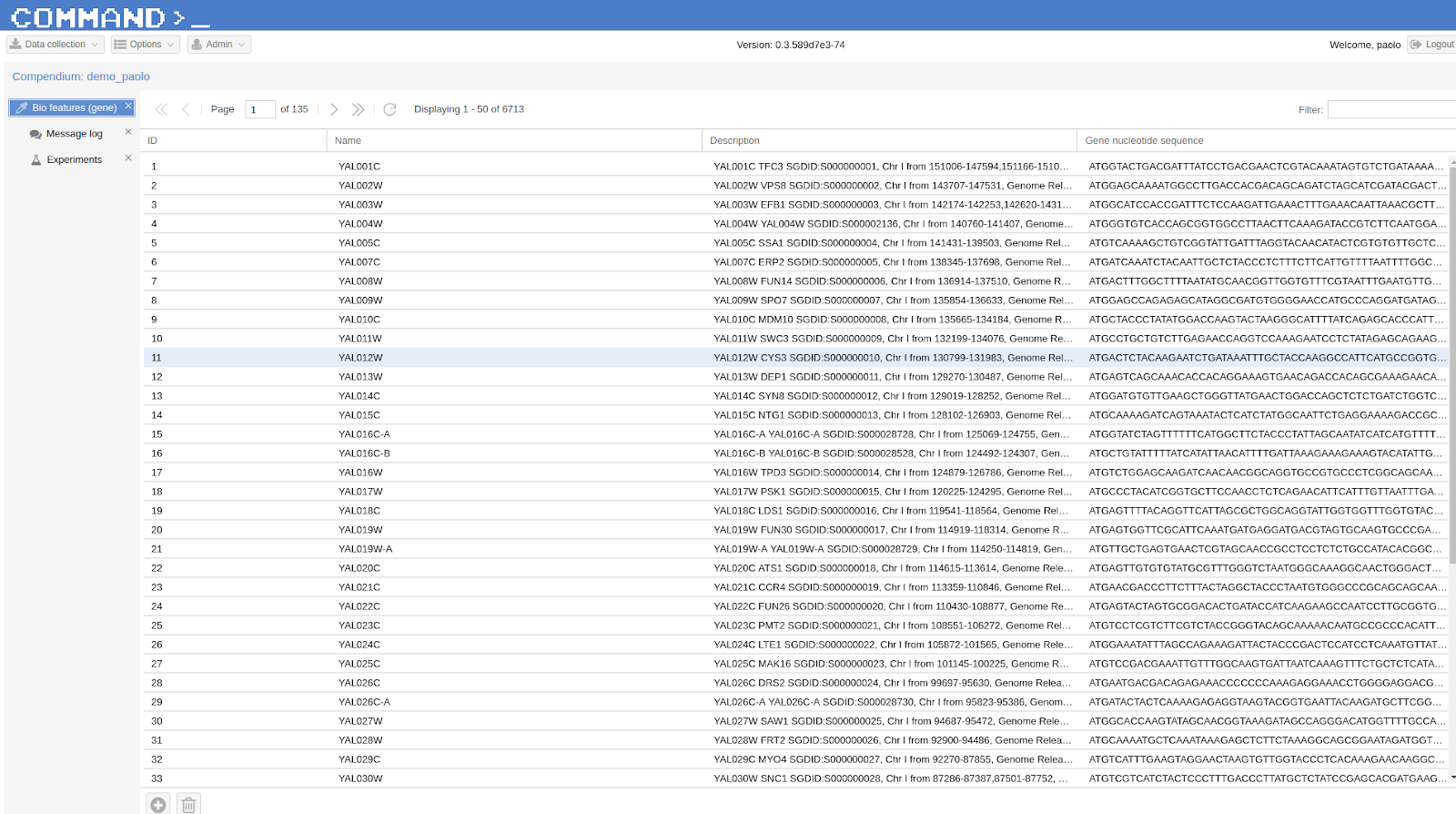
We start by selecting Experiments from Data collection (top left corner) then we highlight the experiment of interest (it was previously retrieved from GEO following Searching public databases), here GSE8536, an expression analyses study which inspects the response of Saccharomyces cerevisiae to stress throughout a 15-day wine fermentation.
Parse Experiment, Platform and Samples¶
Since we have a new platform (GPL90) never imported before into COMMAND>_ for this compendium, we retrieve the sequences associated to the Affymetrix probe ids (YG_S98 probes) for this platform from the Affymetrix Support sitewebsite.
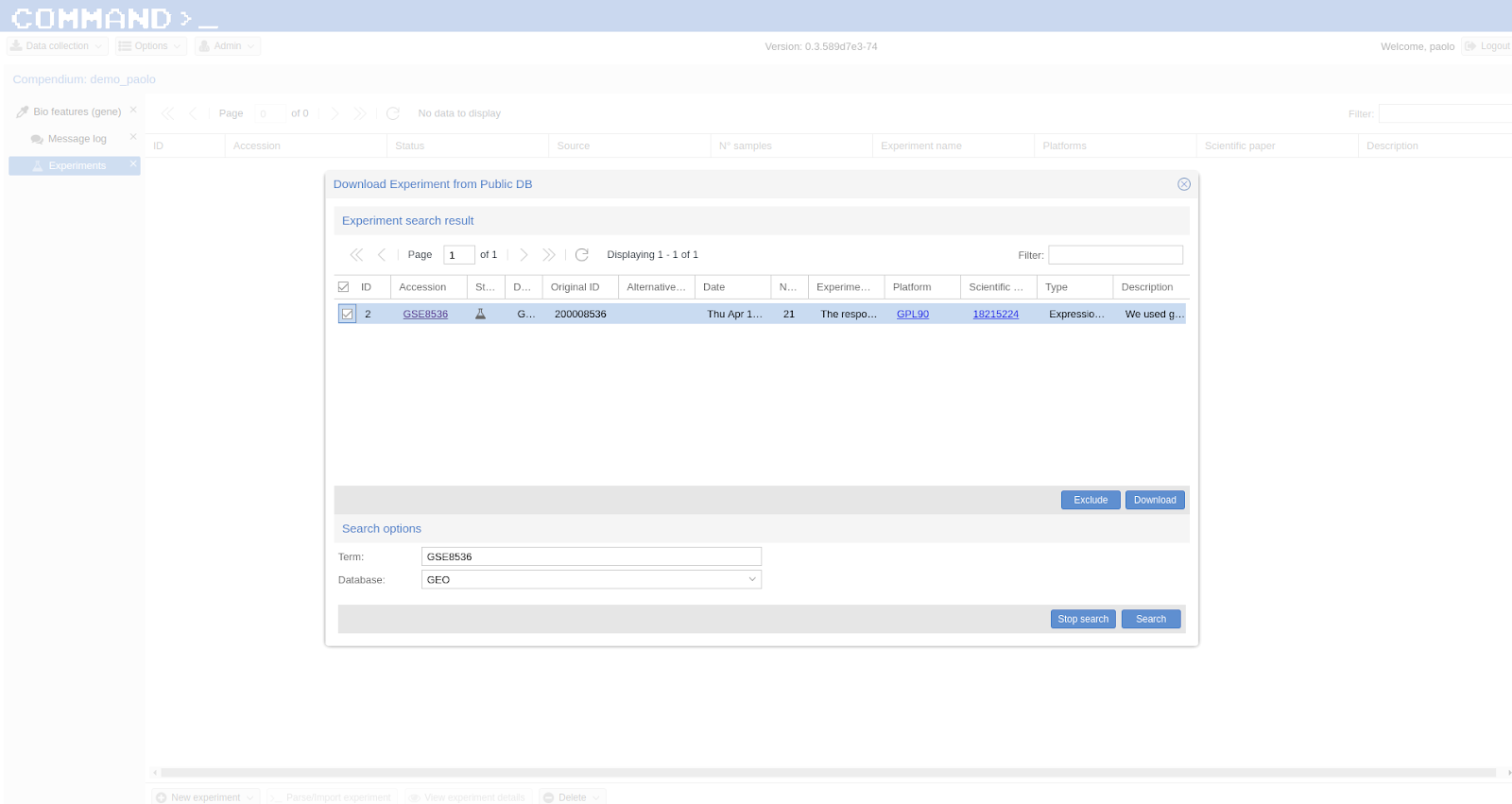
From Experiments (Data collection Menu) we highlight the selected experiment (GSE8536 here) and click the Parse/Import experiment from the bottom bar. On the main window you can see that the Experiment tab is populated with metadata gathered from the publicDB (GEO here). Now we can start parsing the Experiment, the Platform(s) and the Samples.
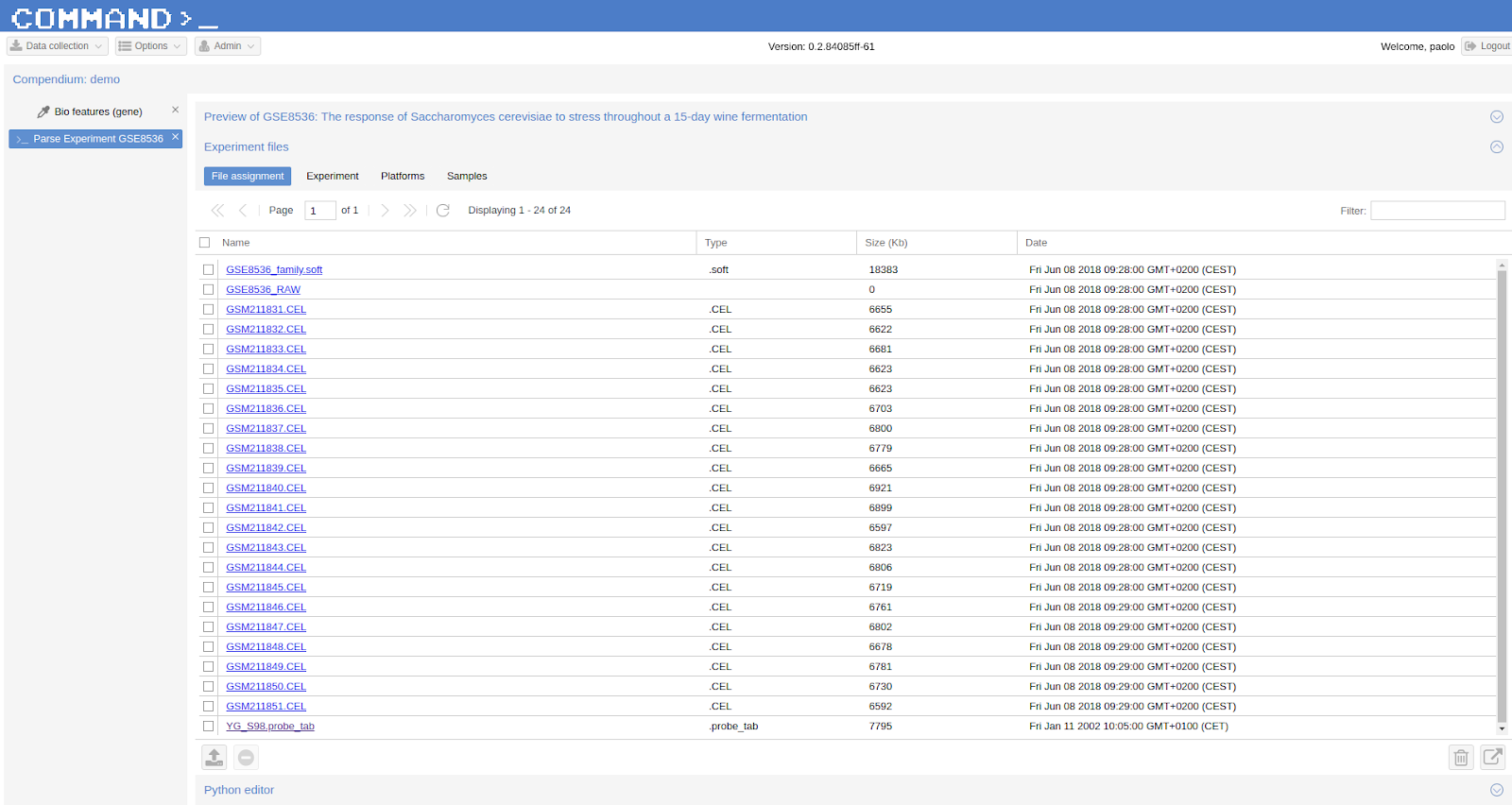
Being a dataset retrieved from GEO we take advantage of the .soft file downloaded (see GEO Documentation for a description of this type of file):
Select GSE8536_family.soft and click the Use assignment script to assign files to experiment entities icon on the bottom-right. A dialog will show-up:
- Script > assign_all.py > Only selected files
- Experiment tab > Script: > soft_experiment.py, Execution order: 1
- Platform tab > Script: > soft_platform.py, Execution order: 1
- Sample tab > Script: > soft_sample.py, Execution order: 1
- Run assignment script
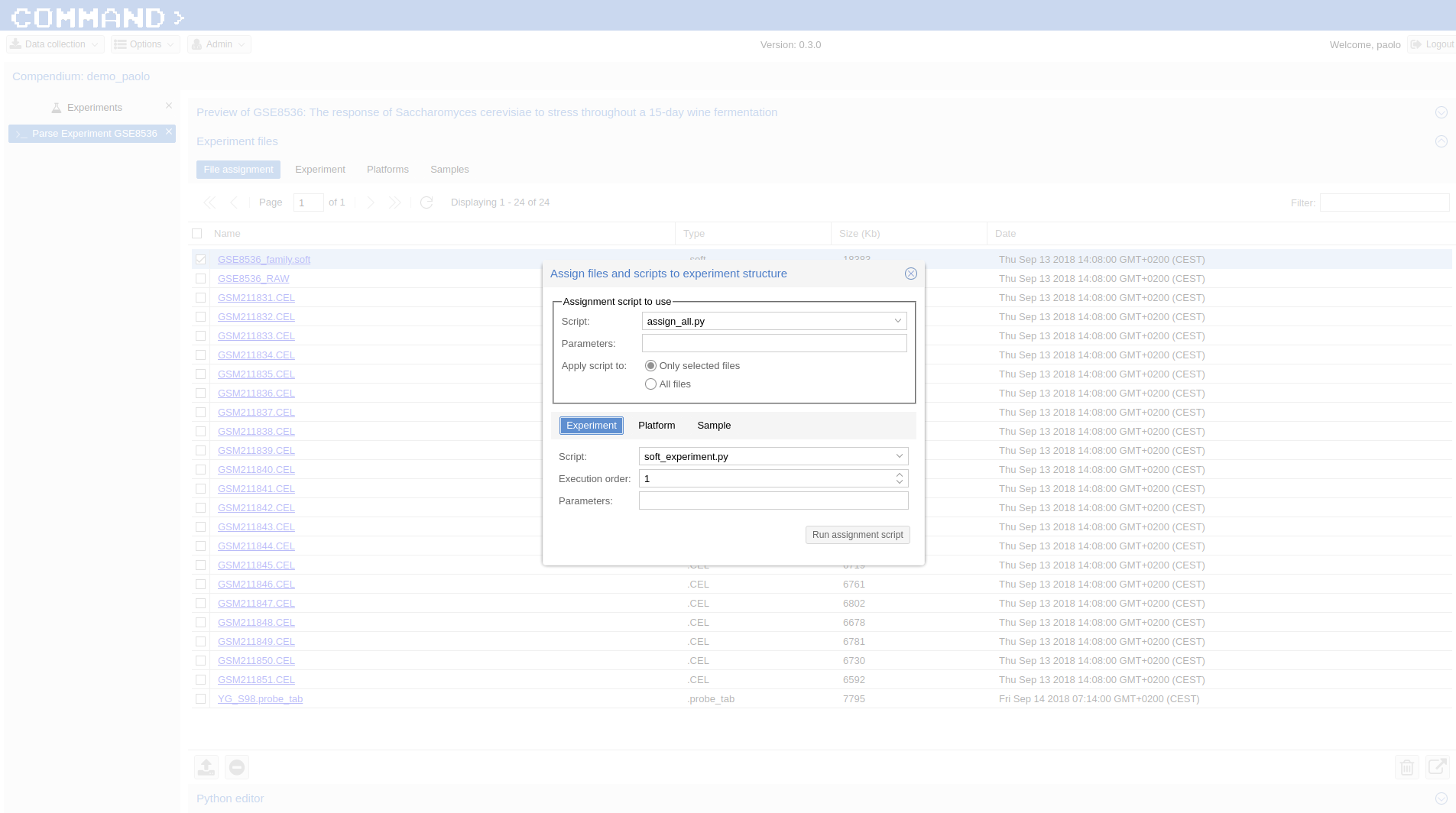
Now in order to parse the new platform we are going to use the sequences associated to the Affymetrix probe ids we have already downloaded. We import the annotation ( YG_S98 probes ) in the File assignment section of Experiment files clicking the upload icon on the bottom of the page.
Now we associate the file to the platform:
- In Experiment files Section > File Assignment select the uploaded file (YG_S98.probe_tab) and click Use assignment script to assign files to experiment entities. On the Assign files dialog:
- Script: assign_all.py
- Param:
- Only selected files checked (default)
- Platform tab > Script: gpr_platform.py , Parameters: 0,Probe X|Probe Y,Probe Sequence , Execution order: 2
- Run assignment script
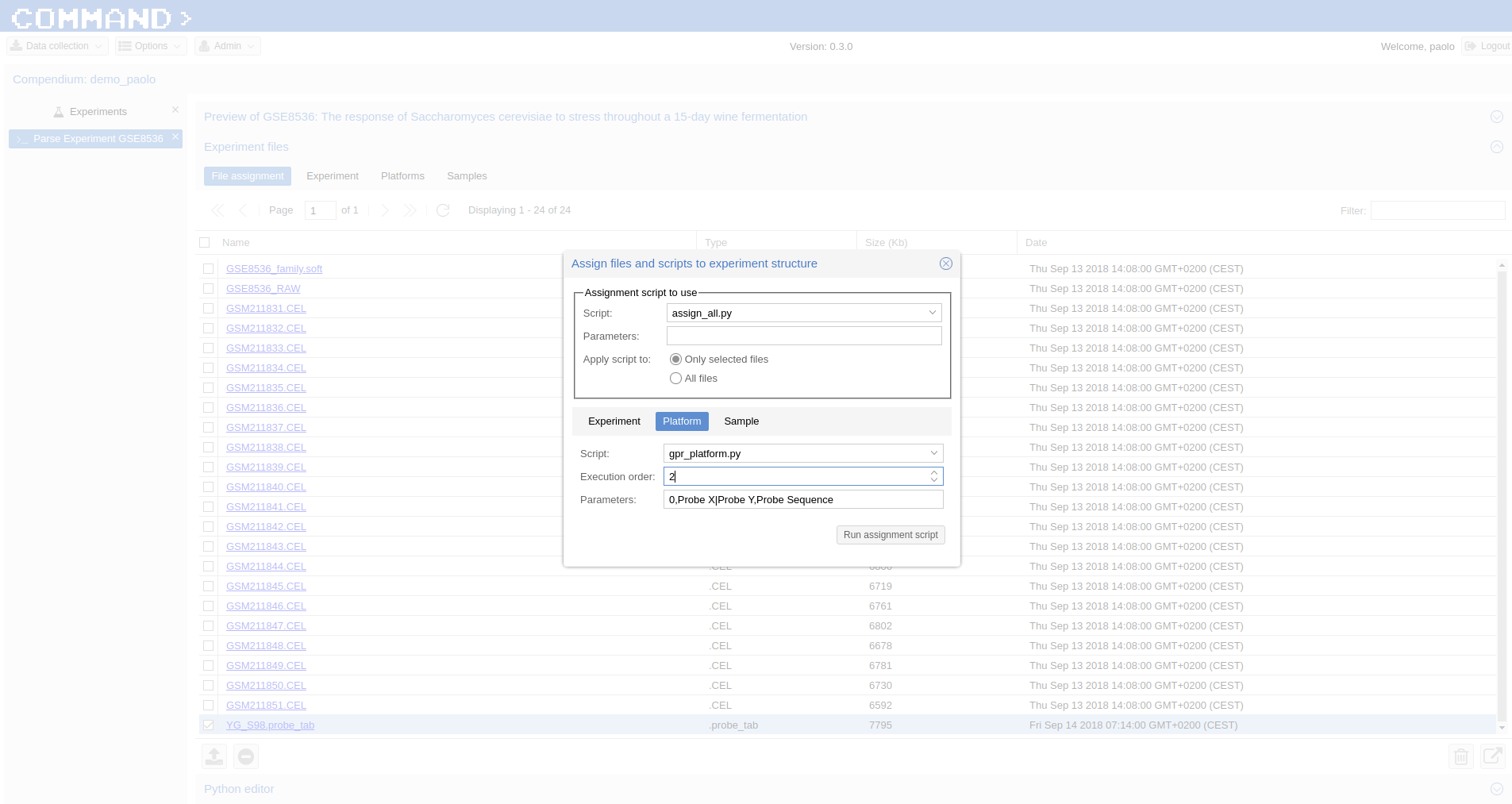
Note
- the Parameters assigned to the gpr_platform.py script specify to not skip any line, use the combination of Probe X and Probe Y columns to create an unique id for the cel files and indicate the sequences for the probes are in the Probe Sequence column.
- The parsing of the Platform is a once time procedure: from now on we can use this platform for all related experiments.
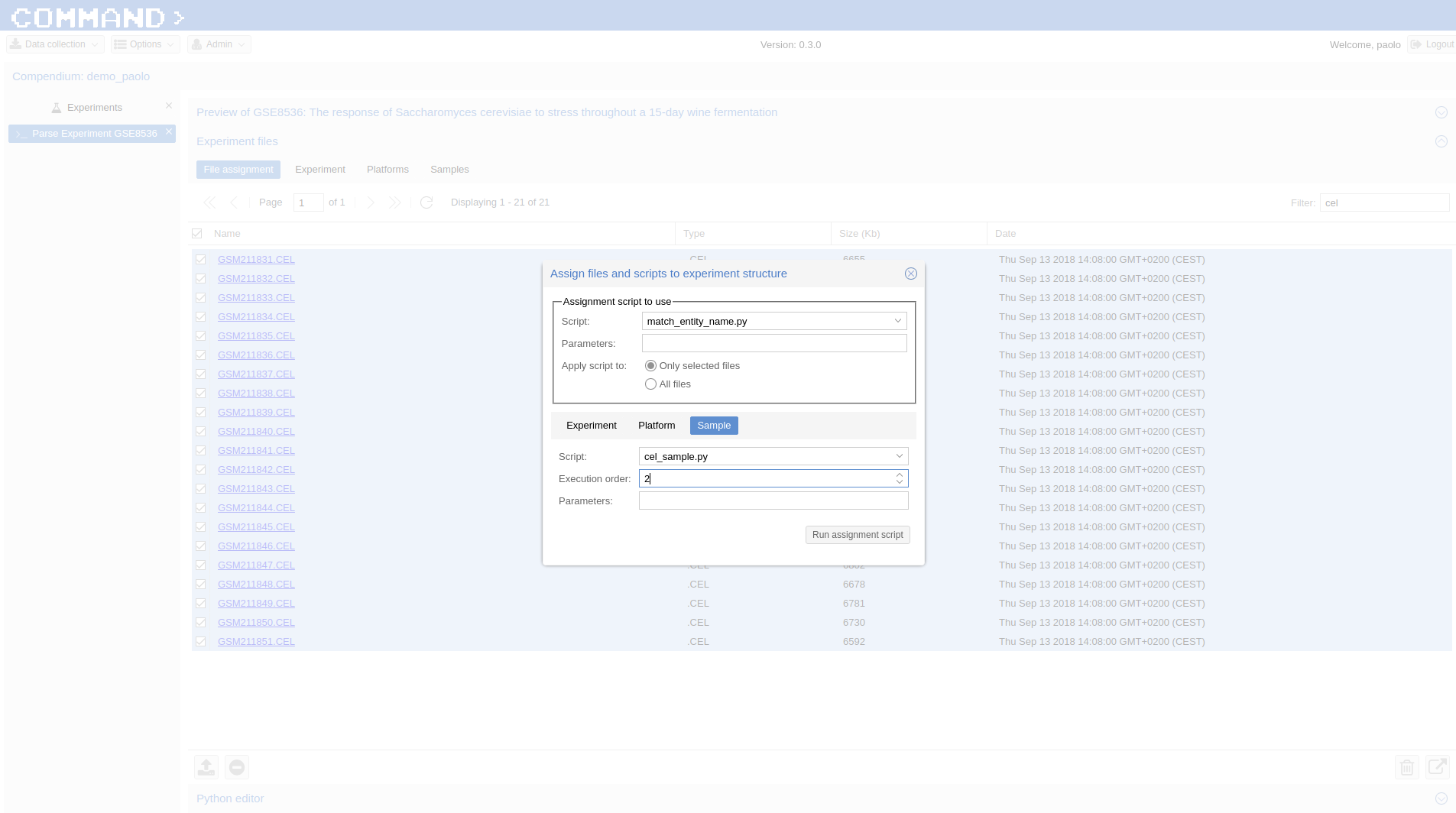
Now we parse the Affymetrix cel files (sample files):
- In Experiment files Section > File Assignment we use CEL as filter and select all files > click the Use assignment script to assign files to experiment entities icon on the bottom-right corner and the Assign files and scripts to experiment structure dialog will pop-up:
- Script > match_entity_name.py
- Only selected files (default) checked
- Sample tab > Script: cell_sample.py, Execution order: 2
- Run assignment script
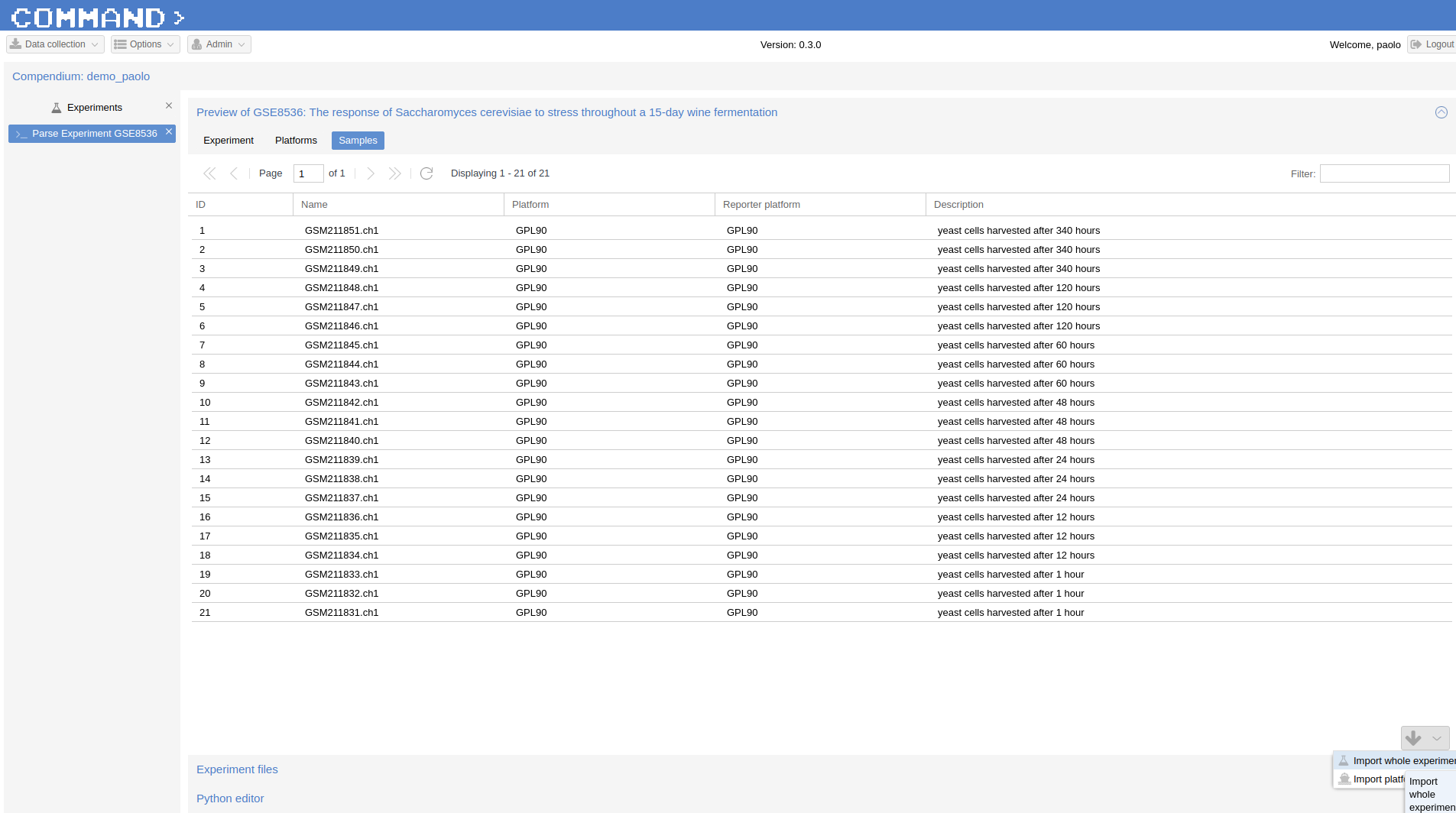
Finally, in the Preview Section (Preview of GSE8536 here) click Run Selected (bottom-right corner). After a while your samples will be parsed.
Now you can Import both the Platform (since is the first time we use this specific one) and the Experiment.
Tip
Check that both the platform and the samples are properly parsed from the Preview interface of the Parse Experiment section clicking on the platform and on each sample.
Click the Import button on the bottom-right corner and select Import whole experiment. After a while the experiment and the platform (in this case) will be imported.
Use Case - Nimblegen from ArrayExpress¶
In COMMAND>_ the preferred way to import experiments from public db is by using GEO which provide the most convenient interface out-of-the-box. In case an experiment is not included in GEO it is possible to import it from ArrayExpress. Start by searching the experiment of interest following the procedure described in Searching public databases, select E-GEOD-58806 as Term and ArrayExpress as Database. Go the experiment slide on the left, select the experiment of interest (here E-GEOD-58806 ) and click >_ Parse/Import experiment. On the main window you can see that the Experiment tab is populated with metadata gathered from the publicDB (ArrayExpress here).
Import Platform from GEO¶
COMMAND>_can use a previous imported platform from a different public database (either ArrayExpress or GEO) and assign it as Reporter platform (in the preview main section of Parsing) for the current experiment.
In our case we want to parse and import an experiment from ArrayExpress using a previously imported platform from GEO. In order to do so we import ONLY the platform for another experiment (here GSE32561) which uses the same platform of the experiment of interest. After the selection of the new experiment using the Searching from public db procedure we use the Nimblegen ndf files which allows to associate probes to sequences to the platform GPL14649.
Experiment files > File Assignment > Select GPL14649_071112_Ecoli_K12_EXP.ndf and in the Assign files dialog:
- Script: match_entity_name.py
- Param: platform
- Only selected files checked (default)
- Platform tab > Script: > gpr_platform.py; Parameters: 0,X|Y,PROBE_ID; Execution order: 2
- Run assignment script
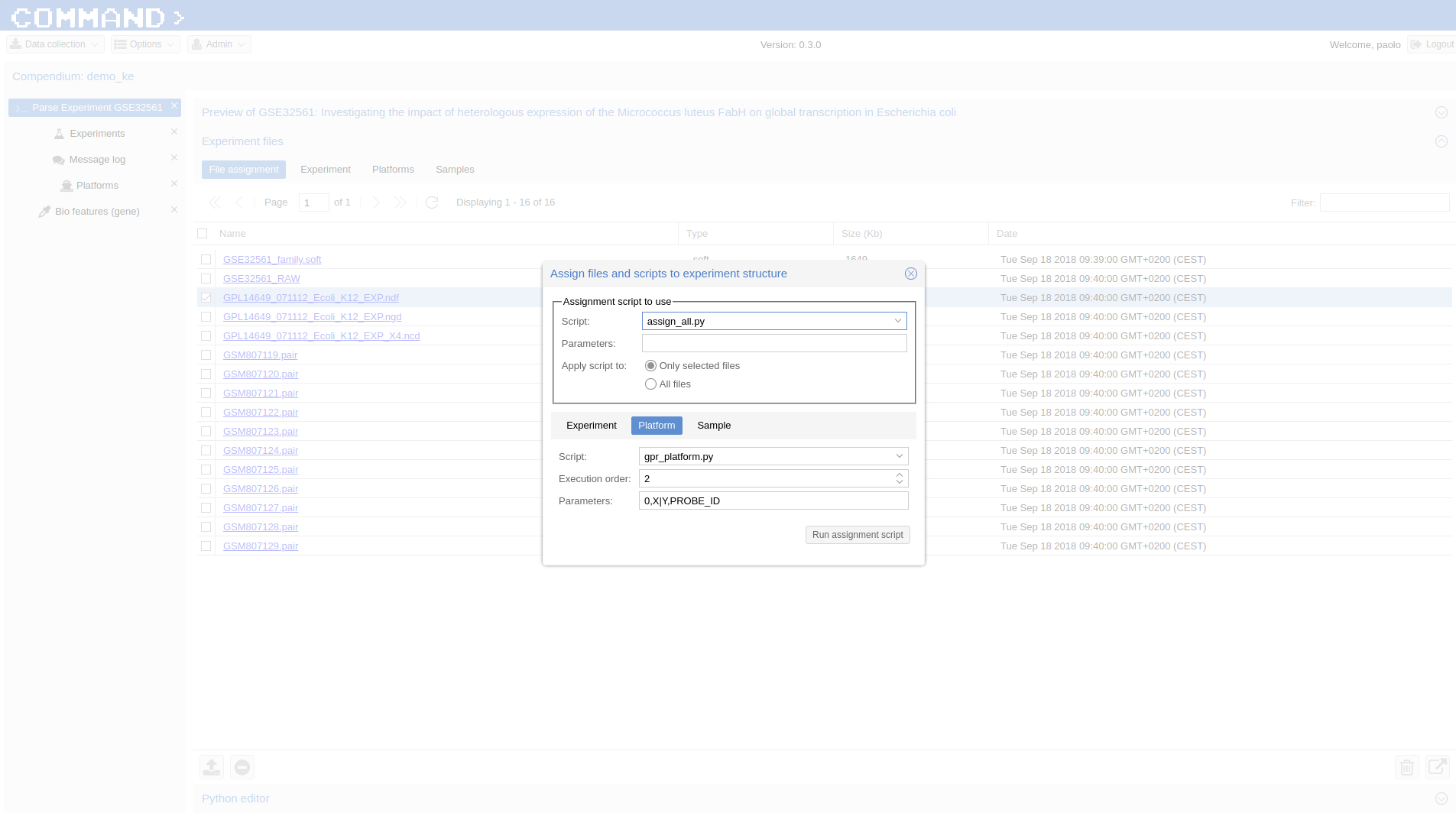
Now we can import this platform from the Platform section of Preview:
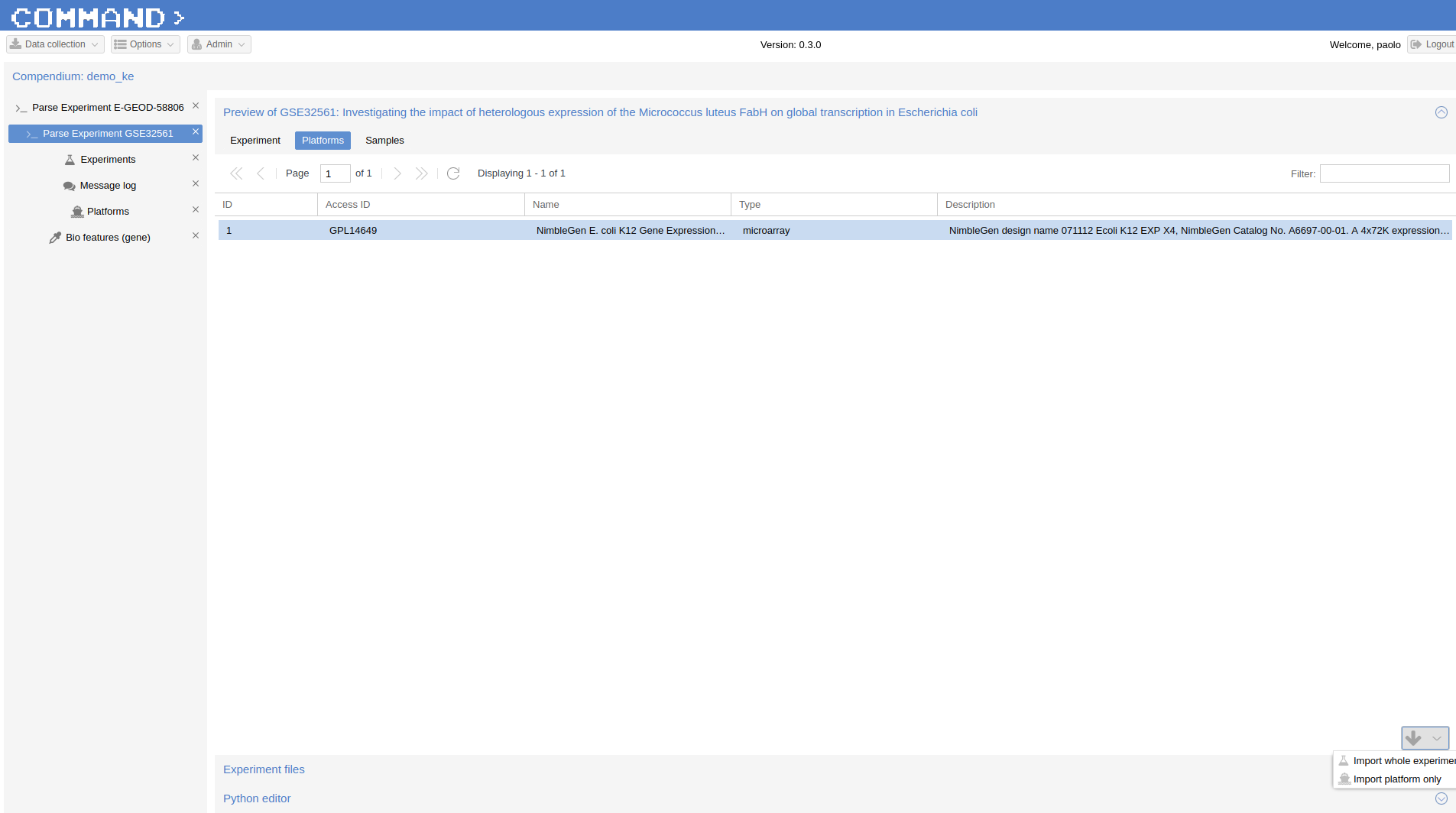
Parse Experiment, Platform and Samples¶
Now the Platform is available and can be used to import the experiment retrieved from ArrayExpress. Go to Experiments > Parse Experiment E-GEOD-58806 > Experiment Files > Platform and now click over A-GEOD-14649 in the Reporter Platform field and selected the previously imported GPL14649.
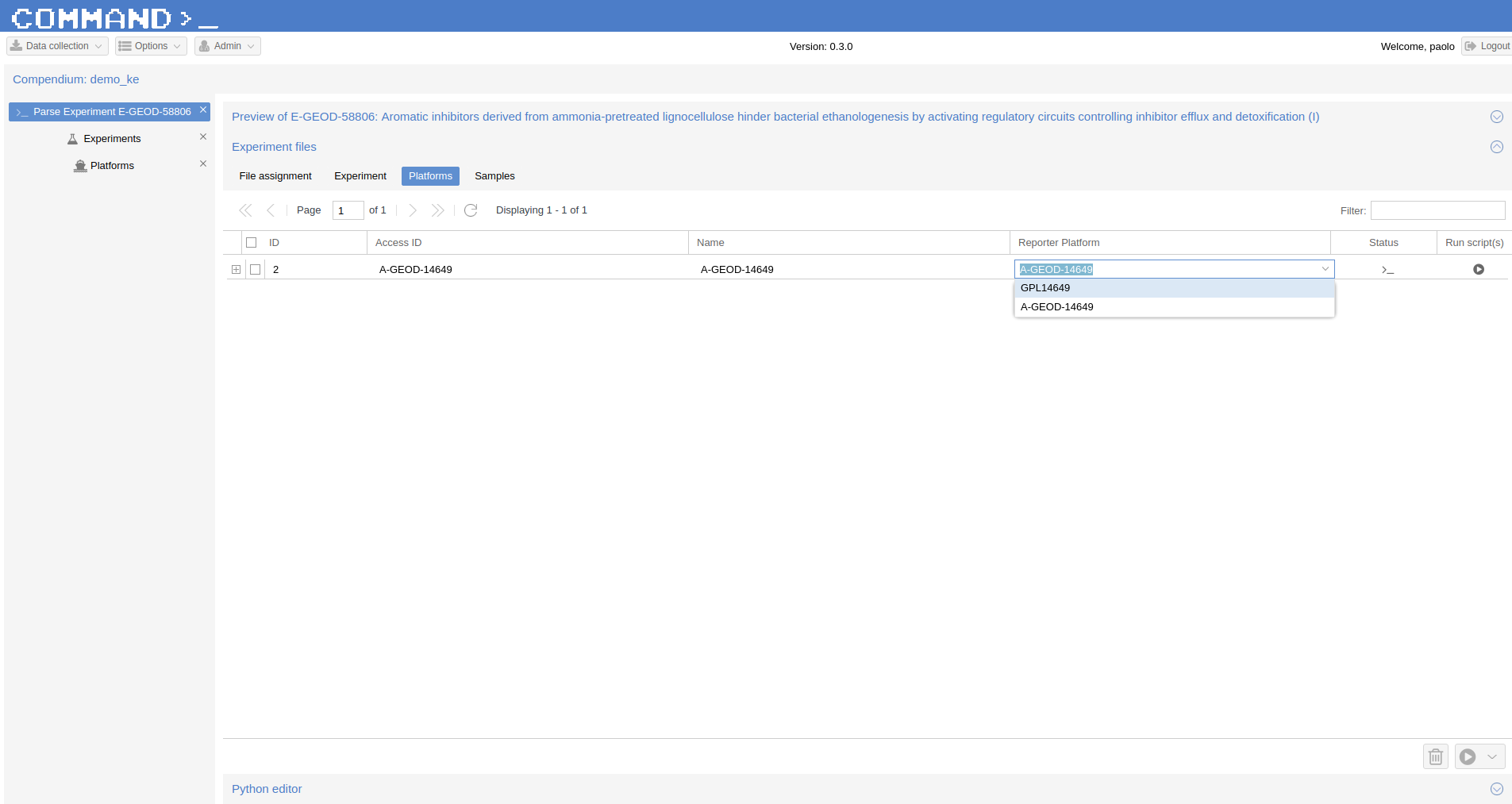
Finally you parse and import the nimblegen .pair files:
- In Experiment files Section > File Assignment > Filter .pair and select all files
- click the Use assignment script to assign files to experiment entities icon on the bottom-right and the Assign files and scripts to experiment structure dialog will pop-up:
- Script: match_sample_name.py > Only selected files
- Sample: Script: > pair_sample.py, Execution order: 2
- Run assignment script
Use Case - Multiplatform Experiment¶
It is standard practice for gene expressione esperiments to make use of multiple platforms for the same organism in the same experiment: usually it comes from multiple single experiments performed in different conditions/time. Here, we select from GEO the GSE13713 experiment regarding Phenotypic and transcriptomic analyses of mildly and severely salt-stressed Bacillus cereus ATCC. It is related to two platforms: GPL7634 and GPL7636.
Import Gene Annotation¶
Since the platforms related to the selected experiment were never imported before into COMMAND>_, we need the gene sequences in order to properly import our probes at gene level. We got gene/sequence list from ncbi: go here and from the top-right button select send to: Coding sequences, Format: FASTA Nucleotide and Choose destination: File. In COMMAND>_ go to > Data Collection (on the top left corner) then > Bio features (genes) > Import biological feature (+ symbol on the bottom left) > Type: FASTA , File name: select the annotation file you downloaded before > Import Biological features.
Parse Platforms and Samples¶
In order to parse the two platforms, we need both the soft file related to the experiment and the soft_platform.py script.
In Experiment files Section > File Assignement > Select the GSE13713_family.soft file and on the Assign files dialog:
- Script: match_all.py
- Param: platform
- Only selected files checked
- Platform tab > Script: > soft_platform.py, parameters: True, Execution order: 1
In Experiment files Section > File Assignement > Select the .txt files (all Sultana in the Filter field) and on the Assign files dialog:
- Script: match_entitye_name.py
- Parameters: ch1
- Only selected files checked
Platform tab
- Script: gpr_sample.py
- parameters: Gene name,Spot Mean Intensity (Cyanine5_060909_1136(1)),0
- Execution order: 2
Do the same again for the ch2 but use as Parameters for Platform:
Platform tab
- Script: gpr_sample.py
- parameters: Gene name,Spot Mean Intensity (Cyanine3_060909_1136(1)),0
- Execution order: 2
for Platform GPL10439:
In Experiment files Section > File Assignement > Select the .ndf file and on the Assign files dialog”:
- Script: match_entity_type_param.py
- Param: platform
- Only selected files checked
- Platform tab > Script: > soft_platform.py, Execution order: 2
In Experiment files Section > File Assignement > Select the .txt files (all pair files) and on the Assign files dialog:
- Script: match_entity_name.py
Parameters: ch1
- Only selected files checked
- Platform tab > Script: > gpr_sample.py; Execution; order: 2
- Parameters: ID_REF,Spot Mean Intensity (Alexa555_101810_0935(1)),0
Parameters: ch2
- Only selected files checked
- Platform tab > Script: > gpr_sample.py; Execution; order: 2
- Parameters: ID_REF,Spot Mean Intensity (Alexa647_111510_1227(1))
Use Case - Import experiment from local file¶
In order to import an experiment which is not available from public repositories the user needs to provide:
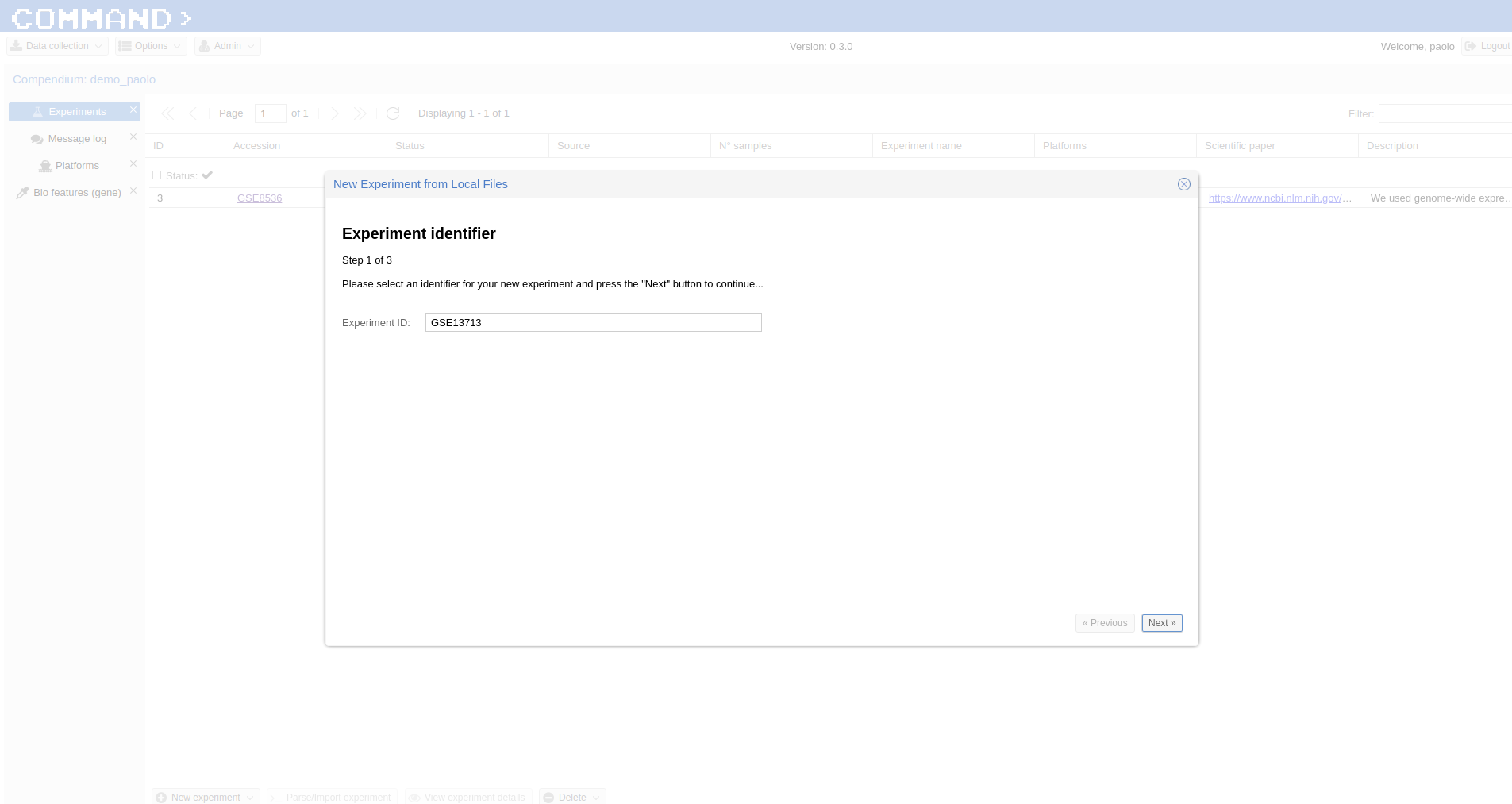
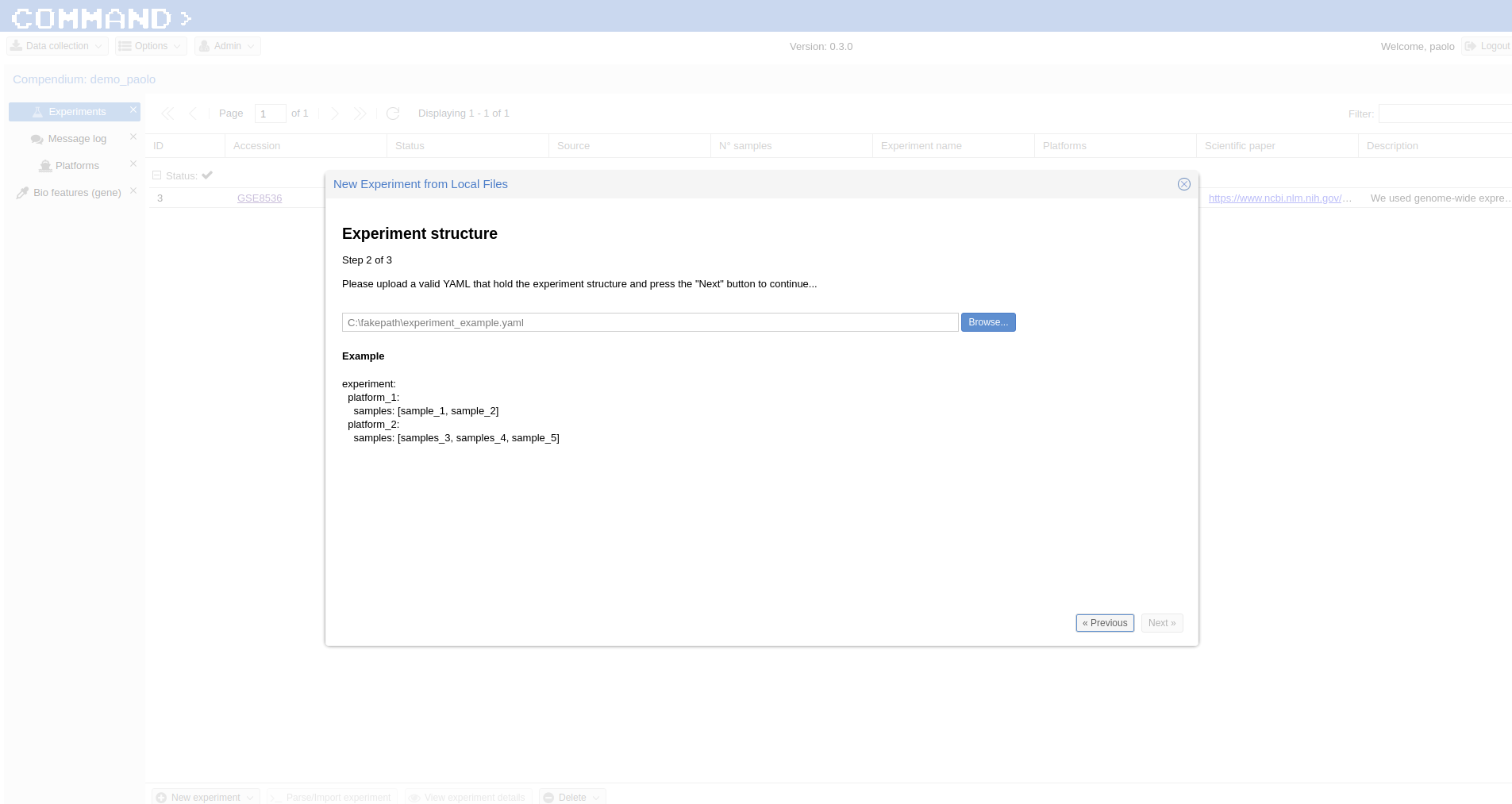
- a yaml file (see an example:
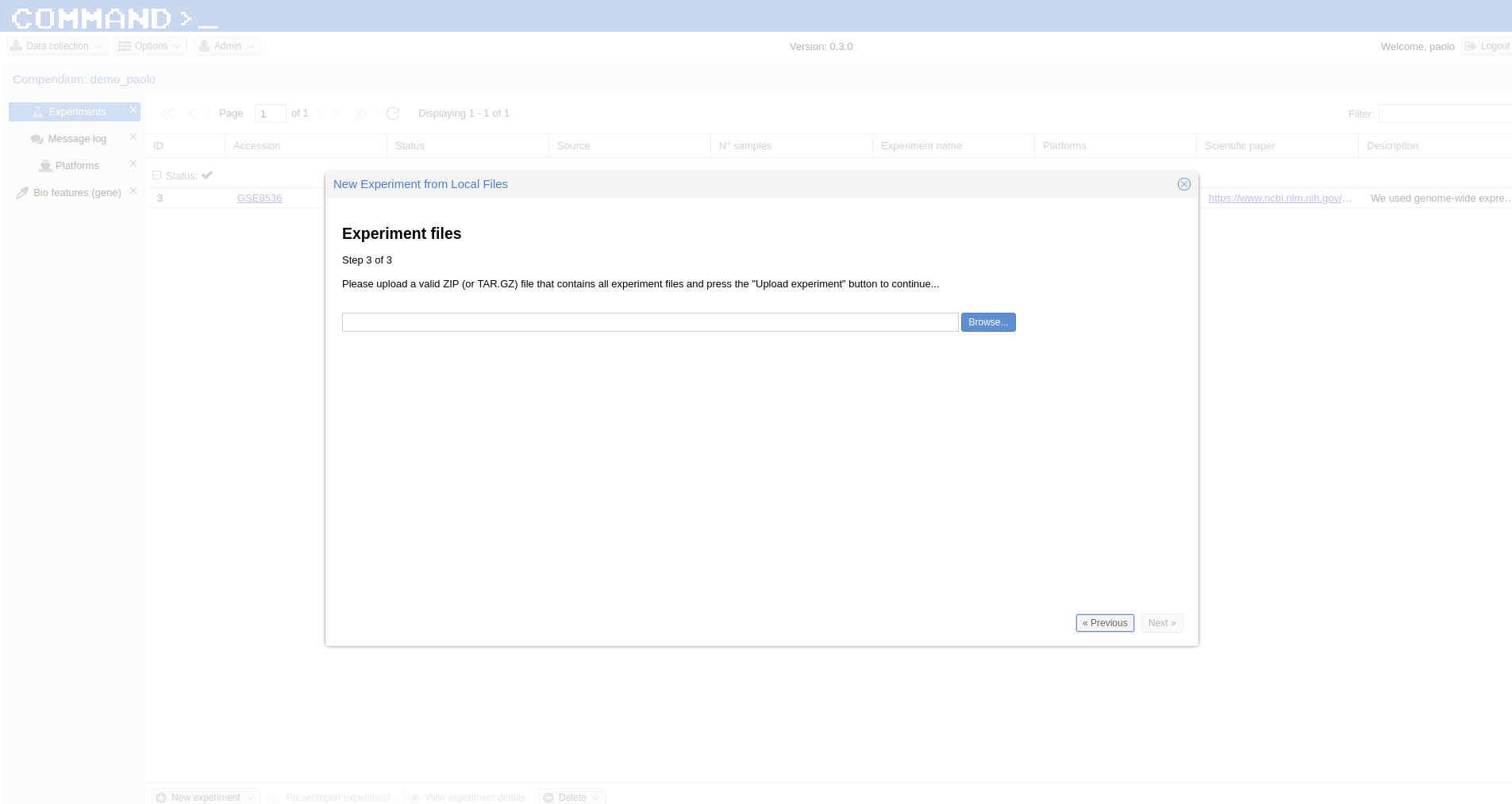
here) containing the description of the experiment to be imported: The first row contains the Experiment id, the other rows start with the Platform id followed by the Samples ids. - a single compressed file (either zip or tar.gz) containing the raw data.
Go to Experiments > New Experiment (bottom-left) > From local file
Fill the form which popped up starting with Experiment ID (the same contained in the yaml file, GSE13713 for the embedded example) then upload the yaml file (the system will take care to check if the format is ok), finally upload the compressed data. In a while your experiment is going to be imported.
Use Case - RNA-Seq¶
Similarly to the microarray cases, RNA-Seq experiments can be retrieved from public database, specifically the Sequence Read Archive (SRA) , from the New Experiment/From public DB interface (bottom-left border icon). Here we select a small RNA-Seq experiment from SRA (PRJNA471071) where the authors employed a computational model of underground metabolism and laboratory evolution experiments to examine the role of enzyme promiscuity in the acquisition and optimization of growth on predicted non-native substrates in E. coli K-12 MG1655.
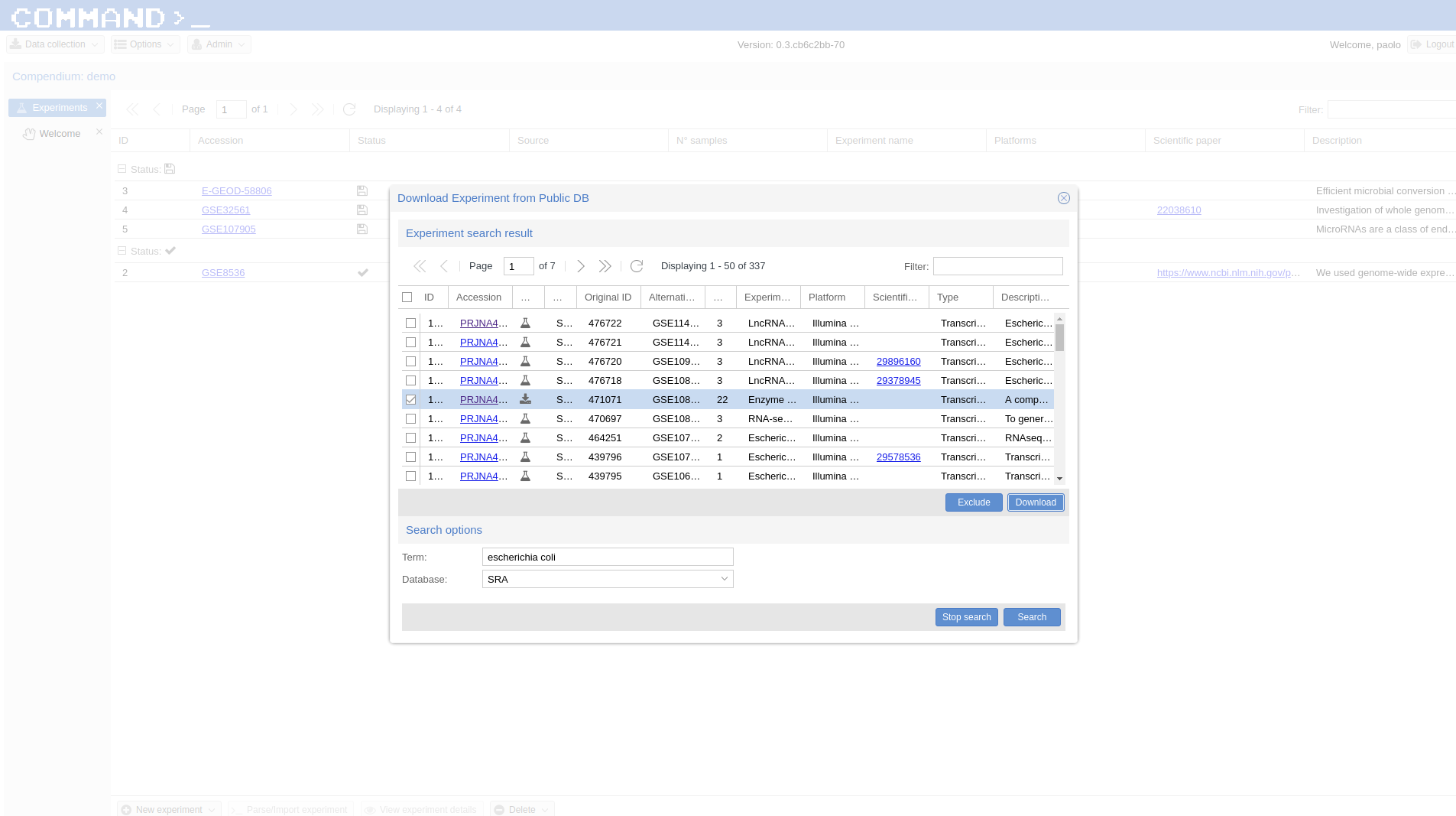
Indexing¶
The first step is to build the index for the quasi-alignment mapper (kallisto here [1]): select demo.fasta, It contains the sequences for the genes of the Escherichia coli genome and it is automatically build by COMMAND>_ when you begin parsing the data.
Use Assignment Script (bottom-right corner icon) > from the dialog:match_entity_name.py > Only selected files Experiment tab > Script: > kallisto_index.py, Execution order: 1 > Run assignment script
RNA-Seq pre-processing and summarization¶
Since the experiment is paired-end, the default script for preprocessing and summarization requires to indicate only one of the two paired files. You can do it using the filter and selecting *1.fastq, the script will take care of the rest.
Use Assignment Script (bottom-right corner icon) > from the dialog:match_entity_name.py > Only selected files Experiment tab > Script: > trim_quantify.py, Execution order: 1, Parameters: 1 (being a paired end)
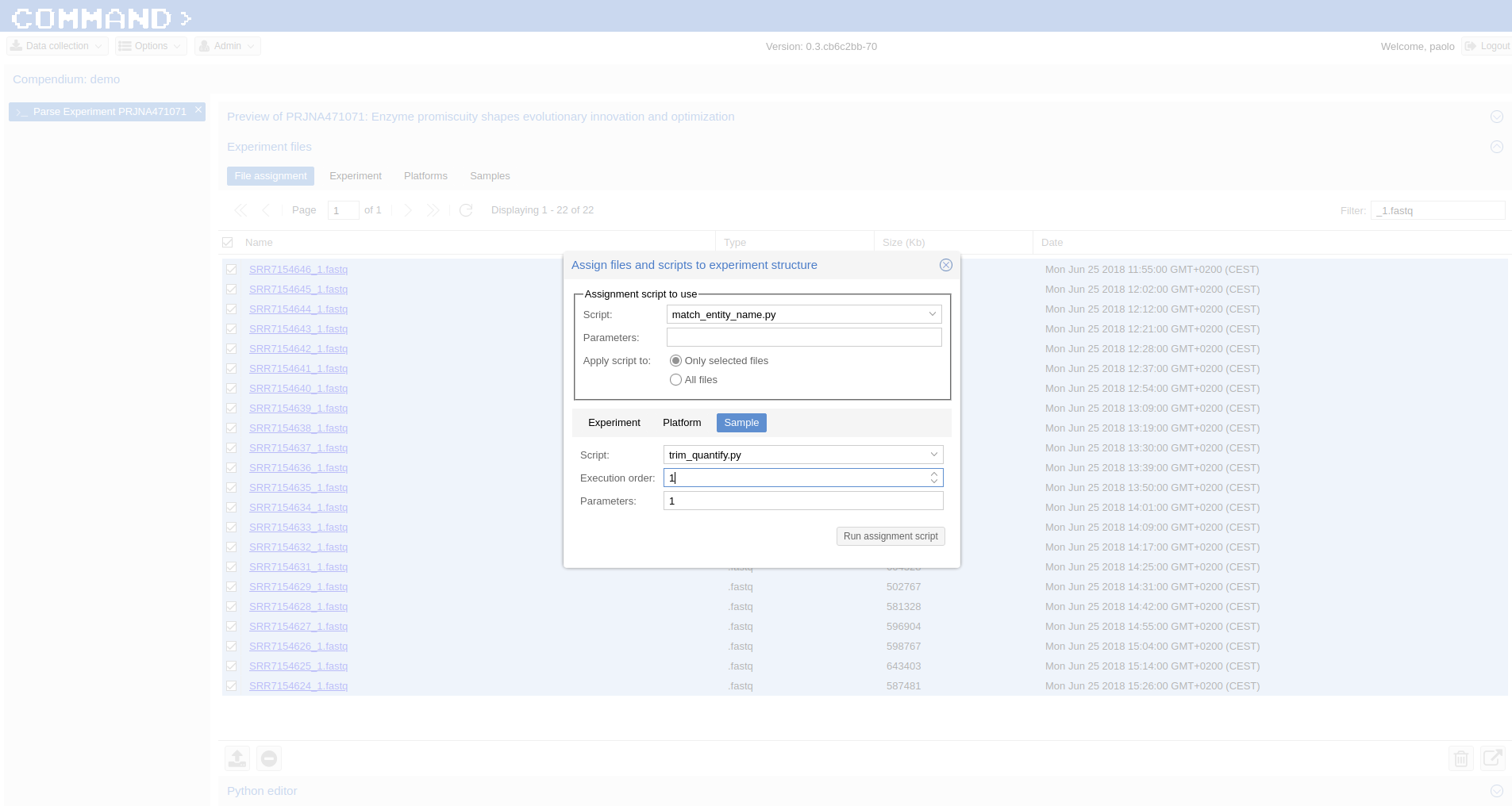
Run assignment script¶
After a while all the sample will be preprocessed and summarized and the experiment can be imported from the Preview section: bottom-right corner > Import whole experiment.
Mapping probes and export the gene expression matrix¶
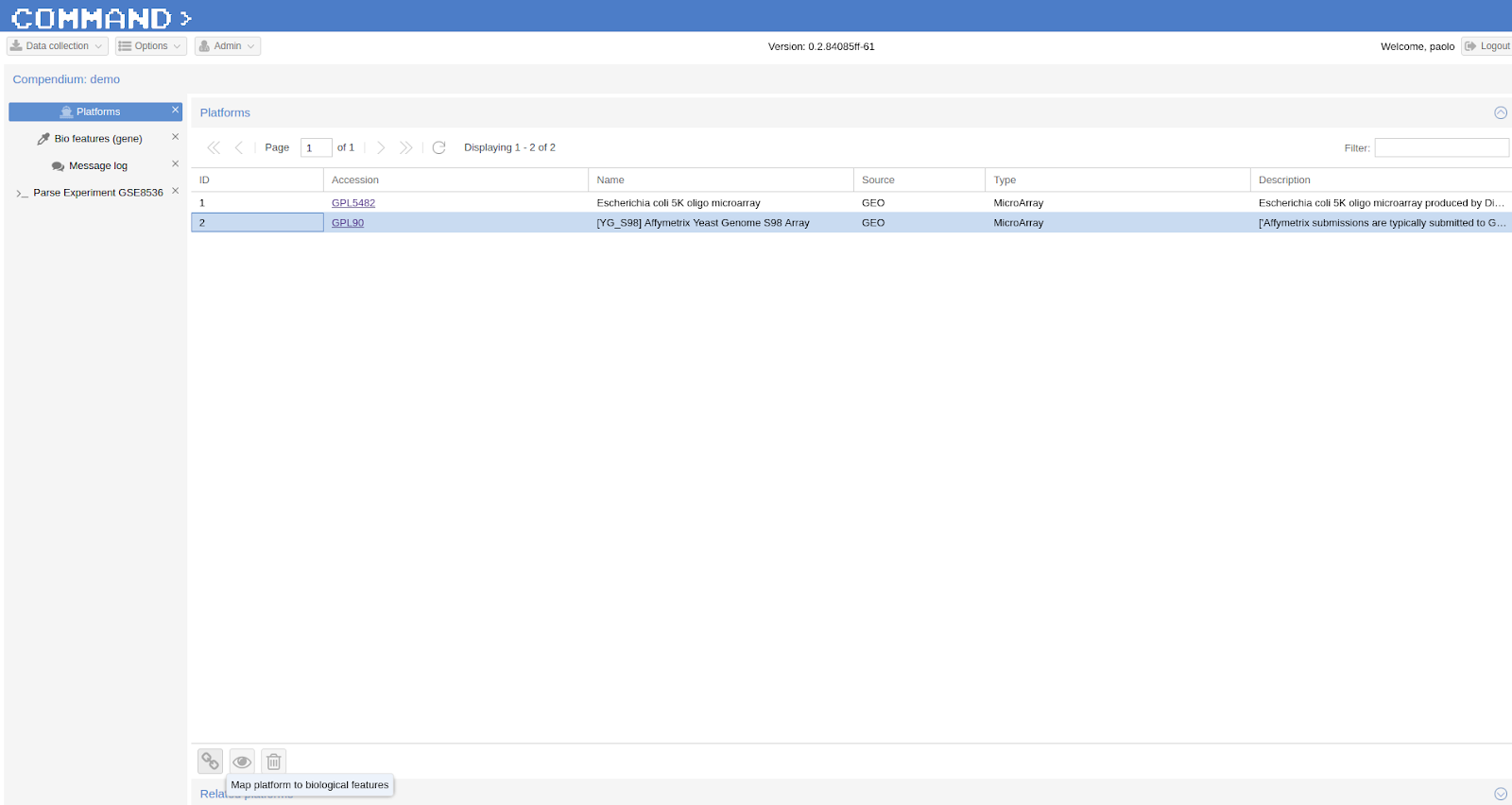
If you are done with importing experiments you can now map the probes to genes using BLAST [2] and a double filtering GUI of COMMAND>_. Go to Platform, select the platform to be mapped (e.g. GPL90 from the Affymetrix Use Case) and click the chain icon (map platform to biological features) on the bottom left corner.
Now you can use the dialog to run BLAST and filter the data (here we use the default settings).
When your are fine with filtering you can use one of the selected filtered objects and download the expression matrix going to Options > Export.
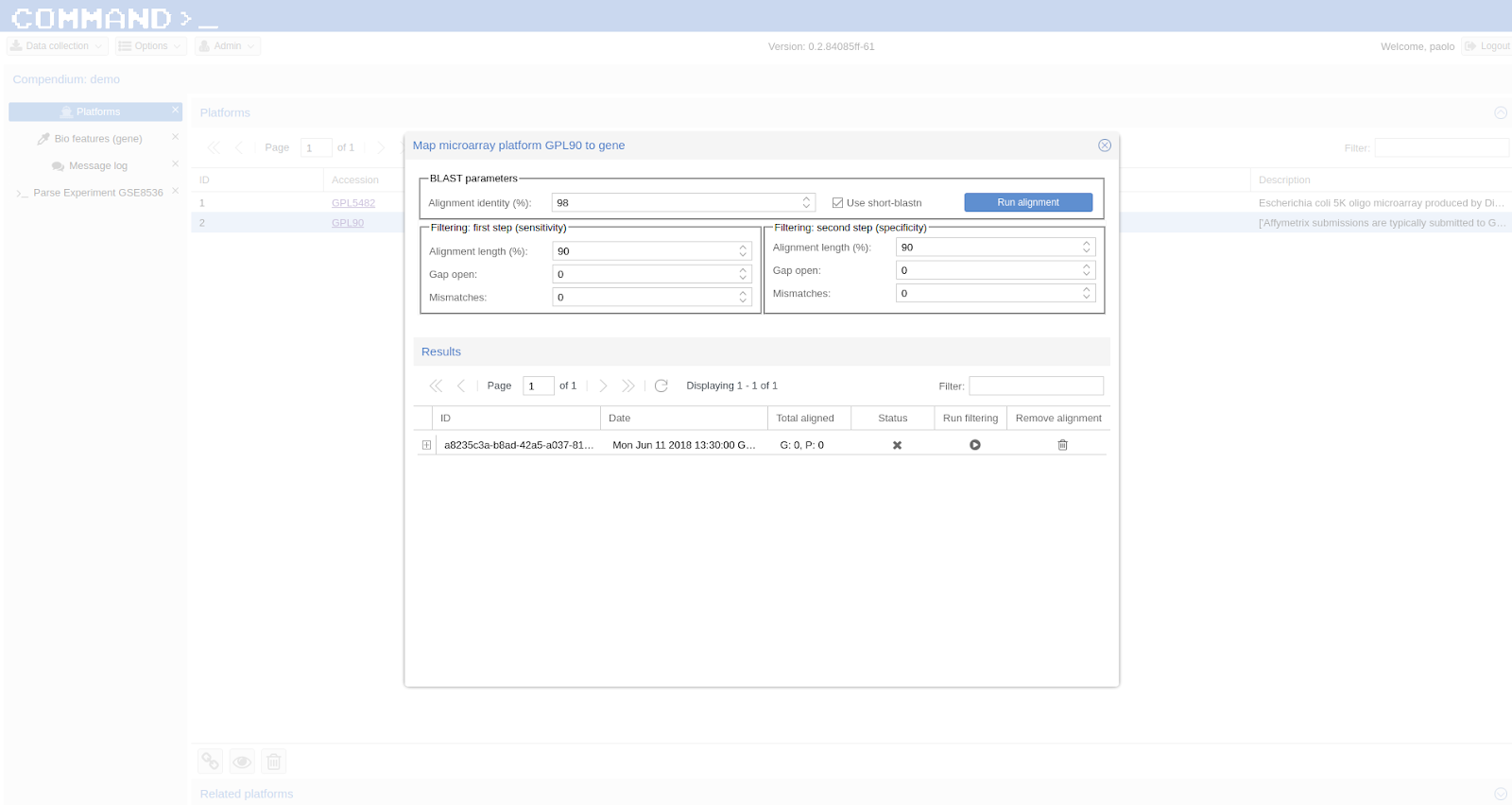
Tip
You can filter the data with different parameters, each set of parameters is saved in a specific slot.
References
| [1] | Nicolas L Bray, Harold Pimentel, Páll Melsted and Lior Pachter, Near-optimal probabilistic RNA-seq quantification, Nature Biotechnology 34, 525–527 (2016), doi:10.1038/nbt.3519 |
| [2] | Altschul, S.F., Gish, W., Miller, W., Myers, E.W. & Lipman, D.J. (1990) “Basic local alignment search tool.” J. Mol. Biol. 215:403-410. |